Warning – personal opinions, not official BBC policy or product announcements, within.
What with the Local and EU Parliament Elections, the Scottish Referendum, and a General Election next May, 2014-15 is a momentous year for UK politics. The BBC has, and will have, a big role to play in bringing coverage and results from these elections to the nation and the world.
Today, I talked to the team at the Government Digital Service about some of the work I, and others I work with, have been doing in the political arena of BBC News Online. Here’s a write up of said talk.
The BBC has a mandate, as part of the Royal Charter, to “encourage citizenship and civil society…by promoting understanding of the UK’s political system.” For ‘Vote 2014‘, the name the BBC gave to the local and EU elections, we used semantic tagging to bring together relevant content from across BBC journalism – traditionally siloed as TV, radio and online, centred around the things that were most important to our users – the councils and constituencies where they live.
There’s a lot more about the work I did, including making sure our tags were linked up to open data sources, in the blog post I wrote for the BBC Internet Blog, back in May. But there’s another side to the BBC’s coverage of Politics, online, aside from day-to-day reporting and election coverage.
Democracy Live is a part of the BBC News website which seeks to directly fulfil the requirement to ‘promote understanding of the UK’s political system’. In essence, it is the equivalent of the BBC Parliament channel on TV. Yet it has some added features – transcripts of the proceedings of most, if not all, of the representative institutions, are made searchable, and there is a page for every representative in each major House or Assembly.
Unfortunately, it is a part of the BBC News website which is also rather siloed. And whilst it has an important role to play, and an appreciative audience within the political class, it runs the risk of super-serving that audience – when surely the point of the clause in the Royal Charter is to bring the political understanding to a much wider audience.
As a result, in my role as Data Architect, working with both BBC News Online and with BBC News Labs (part of the BBC’s R&D division), I’ve recently created a prototype which explores how we might integrate the content and concepts present within Democracy Live, with the rest of BBC News Online. It’s also been a great opportunity for me to get back into the coding game. Having had a taster of Python at the beginning of the year, I’ve used this prototype as a chance for me to learn one of the MVC frameworks for Python, Flask.

the homepage
As part of our tagging effort, we have tags for every MP, every political party and every Government Department. So the first thing I did was build a page for each of these. The page brings together tagged content from across BBC News.
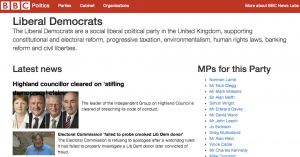
A party page
Importantly, though, I’ve tried to go to authoritative sources wherever possible. The BBC is not the canonical store of knowledge about Parliament or Government. Those institutions are. So, bearing in mind the principle of modular design, and of stitching into the wider Web, I’ve sought to include information from Parliament and Government APIs wherever possible.
For instance, for every Political Party in the prototype, if they have MPs in the House of Commons – I get a list of those MPs from Parliament. For each person, if they’re a member of the Cabinet, I ask GOV.UK for the role they play, and the department that role belongs to. And likewise, for every government department, I ask GOV.UK for the roles, and current role holders, in that department. There’s lots of other things that I could link up, too – GOV.UK has pages for each country the Government has dealings with, and ‘topic’ pages too – just as we’ve been trialling internally at the BBC. Linking these up would give our audiences both the latest news, and engagement with their own Government’s activities in those areas.
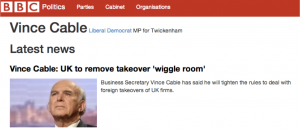
Using Parliament’s APIs to display the seat for an MP

Department and role information using the GOV.UK proxy API
That’s the idea, anyway. In truth, I’ve only been able to get this far because of the limited, but at least slightly useful (and currently being improved upon, I believe), Members Data Platform from Parliament, and a proxy API built by a kind developer at GDS, Camille Baldock. And of course, I’ve had to stitch the two together, maintaining a local store of mappings between IDs and things like that.
This shouldn’t have to be the way it is. Obviously, there is important distance to be kept between the BBC, the Government and Parliament – too closer a partnership, and the political independence of all three is brought into question, also blunting the role of a free press in holding the Government or Parliament to account. But releasing well maintained and structured data about the things each institution is an authority on, and using shared, web-scale identifiers? That should be a given.
As much as each institution will devote time to serving the needs of its’ own specific user base, time and again we have to remember that the concepts are separate from the providers – users don’t see the difference between a politician on GOV.UK, in Parliament or on the BBC – they are one and the same person, and it’s time the Web reflected that.
Of course, joining up information about MPs is only the start. The work that GDS do is brilliant, and quite rightly, they have focused on delivering services to users. But personally, I believe that the part of GOV.UK formerly known as ‘Inside Government’ is an untapped goldmine. It’s not just reference data – it is the cornerstone of the actual material of what Government consists of.
The fact that every Government policy, every statement, every minister, has a publicly addressable URL, and has structured information, is a potentially massive statement about our democracy. No longer does it have to be the case that politicians (and, indeed, the media) can get away with making announcements or press releases that are soon forgotten within the 24-hour rolling cycle of news. The commitments that a Government makes to its’ population are written down and made available to anyone. It’s the closest thing we have to a constitution. And we should be using it to do so much more – holding the Government to account, for instance via linking the latest developments in news, back to the policies, is just one way.
Directly linking the massive audience the BBC has, into GOV.UK, actually showing people that politics isn’t just about spin and publicity (or at least shouldn’t be, if we truly want to at least have a go at being some form of accountable government), is as much about serving users as any of the services the GDS team are working their way through improving right now. Those are important to – they nail people’s necessary interactions with Government – but for civic engagement and democracy? That’s what together, the BBC, Parliament, GDS, and all the other representative institutions (some of which are further ahead in this game – see, for instance, the good work being done with the Northern Ireland Assembly) in the UK, could build, if we work together.




{kind=link}
{kind=link}
{kind=link}
{kind=link}